# MUSDB18
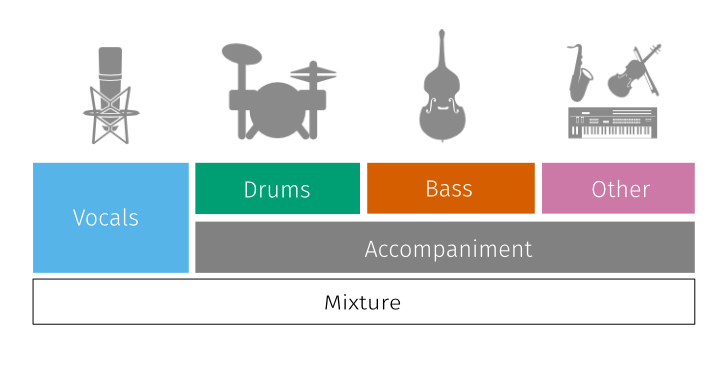
The musdb18 is a dataset of 150 full lengths music tracks (~10h duration) of different genres along with their isolated drums, bass, vocals and others stems.
musdb18 contains two folders, a folder with a training set: "train", composed of 100 songs, and a folder with a test set: "test", composed of 50 songs. Supervised approaches should be trained on the training set and tested on both sets.
All signals are stereophonic and encoded at 44.1kHz.
The data from musdb18 is composed of several different sources:
- 100 tracks are taken from the DSD100 dataset, which is itself derived from The 'Mixing Secrets' Free Multitrack Download Library (opens new window). Please refer to this original resource for any question regarding your rights on your use of the DSD100 data.
- 46 tracks are taken from the MedleyDB (opens new window) licensed under Creative Commons (BY-NC-SA 4.0).
- 2 tracks were kindly provided by Native Instruments originally part of their stems pack (opens new window).
- 2 tracks are from the Canadian rock band The Easton Ellises as part of the heise stems remix competition (opens new window), licensed under Creative Commons (BY-NC-SA 3.0).
A detailed list of all tracks and their respective license is provided here (opens new window).
Note
The dataset is hosted on Zenodo and requires that users request access, since the tracks can only be used for academic purposes. We manually check this requests. Please do not fill the form multiple times, it usually takes as less than a day to give you access.
# MUSDB18 Compressed STEMS

All files from the musdb18 dataset are encoded in the Native Instruments stems format (opens new window) (.mp4). It is a multitrack format composed of 5 stereo streams, each one encoded in AAC @256kbps. These signals correspond to:
0- The mixture,1- The drums,2- The bass,3- The rest of the accompaniment,4- The vocals.
For each file, the mixture correspond to the sum of all the signals.
Note
Since the mixture is separately encoded as AAC, there there is a small difference between the sum of all sources and the mixture. The result of the compression is a bandwidth, limited to 16 kHz. This difference has no impact on the bsseval evaluation performance.
# MUSDB18-HQ Uncompressed WAV

As an alternative, we also offer the uncompressed WAV files for models that aim to predict high bandwidth of up to 22 kHz. Other than that, MUSDB18-HQ is identical to MUSDB18.
Note
If you want to compare separation models to existing source separation literature or if want compare to SiSEC 2018 participants, you should use the standard MUSDB18 dataset, instead.
# Errata
Throughout the years, we found a few errors in the dataset. At some point we are going to fix them and issue a new release:
| Track | Position | Error |
|---|---|---|
| Al James - Schoolboy Facination | synth vocals mixed into other | |
| Chris Durban - Celebrate | bleeding of other instruments into vocals | |
| Detsky Sad - Walkie Talkie | other mixed into drums | |
| Enda Reilly - Cur An Long Ag Seol | speaking at the start of other track | |
| Hop Along - Sister Cities | bleeding of other instruments into vocals | |
| Leaf - Wicked | 2:20, 3:02 | electric-Guitar is mixed into drums |
| PR - Oh No | sum of sources does not add up to the mix for the left channel |
Please open an issue in this repository if you find more errors.
# Tools
# Parsers
- musdb (opens new window): Python based dataset parser
- mus-io (opens new window): Docker scripts for decoding/encoding STEMS <=> wav (i.e. MATLAB users go there)
- musdb.jl (opens new window): Julia based dataset parser
# Evaluation
- museval (opens new window): BSSEval v4 Evaluation tools
# Further Tools
- cutlist-generator (opens new window): Scripts to generate 30s and 7s excerpt annotations from the full dataset based on the activity of all sources.
- preview-generator (opens new window): Scripts to cut and recode the dataset based on provided cutlists.
# Oracle Methods
- oracle (opens new window): Python based oracle method implementation like Ideal Binary Mask, Softmasks, Multichannel Wienerfilter
# SiSEC 2018 Evaluation Campaign
- SiSEC 2018 (opens new window): Raw scores
- SiSEC 2018 - Analysis (opens new window): Analysis of 2018 Submissions
- Paper (opens new window)preprint: all results, to be published at International Conference on Latent Variable Analysis and Signal Separation.
# Acknowledgements
We would like to thank Mike Senior, Rachel Bittner, and also Mickael Le Goff, not only for giving us the permission to use this multitrack material, but also for maintaining such resources for the audio community.
# Authors
- Zafar Rafii
- Antoine Liutkus
- Fabian-Robert Stöter
- Stylianos Ioannis Mimilakis
- Rachel Bittner
# Citation
If you use MUSDB18, please reference it accordingly:
@misc{musdb18,
author = {Rafii, Zafar and
Liutkus, Antoine and
Fabian-Robert St{\"o}ter and
Mimilakis, Stylianos Ioannis and
Bittner, Rachel},
title = {The {MUSDB18} corpus for music separation},
month = dec,
year = 2017,
doi = {10.5281/zenodo.1117372},
url = {https://doi.org/10.5281/zenodo.1117372}
}
if you use MUSDB18-HQ, please cite
@misc{musdb18-hq,
author = {Rafii, Zafar and
Liutkus, Antoine and
Stöter, Fabian-Robert and
Mimilakis, Stylianos Ioannis and
Bittner, Rachel},
title = {MUSDB18-HQ - an uncompressed version of MUSDB18},
month = aug,
year = 2019,
doi = {10.5281/zenodo.3338373},
url = {https://doi.org/10.5281/zenodo.3338373}
}
DSD100 →